
OS - Final Notes
Week 9 - Condition Variables
How to implement what is called the ‘wait function’ for threads?
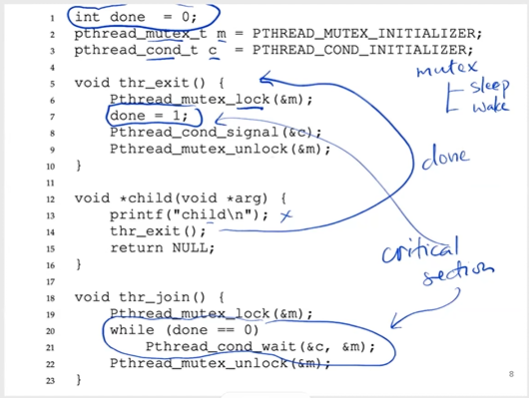
volatile int done = 0;
void *child(void *arg) {
printf("child\n");
done = 1;
return NULL;
}
int main(int argc, char *agrv[]) {
pthread_t c;
pthread_create(&c, NULL, child, NULL);
while(done == 0)
; // spin
print("parent: end\n");
return 0;
}
BUT:
- Using a shared variable ⇒ hugely inefficient as the parent spins and wastes CPU time
- So, need to find way to put the parent to sleep until the condition is true.
NOTE THAT:
- In a single processor, this is a CPU time-wasting way, only one thread can run at a time.
- In the multiprocessor, the spinning is not that bad. Because the child process can run on other CPUs, 2 threads can run at a time in 2 CPUs. So the spinning can be very short.
Definition of a Condition Variable
- Is an explicit queue that threads can put themselves on when some state of execution (some conditions) is not as desired (by waiting on the condition)
- When it changes said state, wake one or more of those waiting threads and thus allow them to continue (by signaling on the condition)
Code

Wait()
- Is to release the lock and put the calling thread to sleep (atomically).
- When the thread wakes up (after being signaled), it must re-acquire (claim) the lock before returning to the caller.
CASE: if there is no ‘done’ variable
- In some cases, the child can finish before going to the join.
- Then, it wakes up no one!
- Then, the parent ‘joins’ and goes to sleep, and never be signaled.
CASE: if there is no ‘lock’
- The parent runs the join() first, it goes to sleep but is interrupted by the system...
- The child then runs, it tries to wake up no one.
- The parent is then resumed, continue to sleep, but never be woken up (the result of no autonomic)
Producer/Consumer’s Problems
- The P/C problem, or sometimes as the bounded buffer problem.
- When: one or more P/C threads
- Producers generate data items and place them in a buffer
- Consumers grab said items from the buffer and consume them in some way
- EX: in a multithreaded web server, piping the output of one program to another...
- Because the bounded buffer is a shared resource, we must, of course, require synchronized access to it.

CASE:
- A producer, that puts an integer into a shared buffer, loops a number of times.
- A consumer, that gets the data out of that shared buffer, runs forever.
PROBLEM:
- A producer puts data into a full buffer
- A consumer gets data from an empty one
NEED:
- The producer needs to know if the buffer is full.
- The consumer needs to know if the buffer is empty.
A Broken Solution
Illustration


CASE: with just a single P/C, then a Broken Solution works, but not for more P/C
Illustration
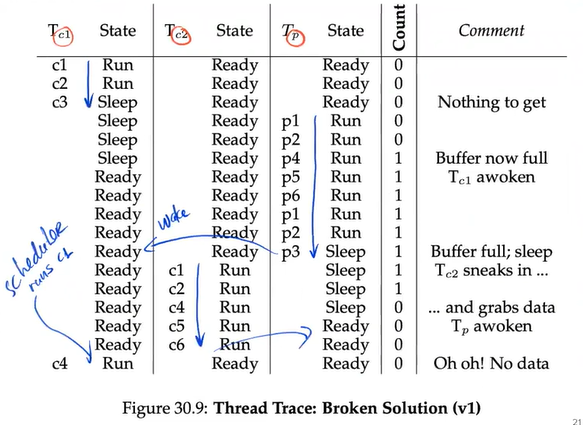
PROBLEM 1:
- In this solution, the condition just signals the thread to wake them up but does not guarantee that it will run
- This interpretation of what a signal means is often referred to as Mesa semantics.
- Virtually every system ever built employs Mesa semantics >< Hoarse semantics, which is harder to be built, provides a stronger guarantee that the woken thread will run immediately.
SOLUTION: use ‘while’ instead of ‘if’
PROBLEM 2: wake up the wrong guy!
Illustration

SOLUTION: use TWO condition variables, one for empty, one for full
Illustration
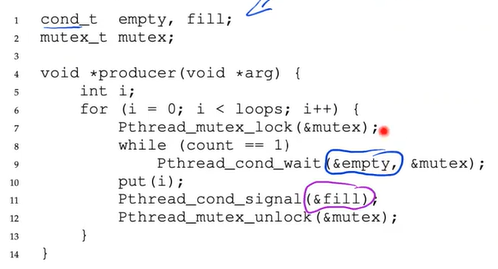

The correct P/C solution
- The last change we make is to enable more concurrency and efficiency; specifically, we add more buffer slots, so that multiple values can be produced before sleeping, and similarly, multiple values can be consumed before sleeping.
- Also, slightly change the conditions that the P/C check in order to determine whether to sleep or not.
Illustration


Week 10 - Semaphore
Definition of Semaphore
- Is an object with an integer value that we can manipulate with two routines; in the POSIX standard, these routines are
sem_wait()andsem_post()
- The initial value of the semaphore determines its behavior → must first initialize it to some value
#include <semaphore.h>
sem_t s;
sem_init(&s, 0, 1);
// 1 is sem value
// 0 is show that the semaphore shares threads in same process.sem_wait()- return right away if semaphore was ≥ 1
- suspend execution waiting for a subsequent post → queued waiting to be woken.
sem_post()simply increments the value of semaphore and wakes a waiting thread up.
- The value of semaphore, when <0, is equal to the number of waiting threads
Binary Semaphore (Lock)
- Using a semaphore as a lock
- Locks only have two states (held and not held) → called a semaphore used as a lock a binary semaphore
sem_t m;
sem_init(&m, 0, X = 1);
sem_wait(&m);
// critical section
sem_post(&m);
NOTE: the init value of X is 1 because the critical section should contain only 1 thread.
Semaphore for Ordering
- Semaphores also useful to order events in the concurrent program
- Ex: a thread creates another thread and then wants to wait for it to complete its execution.
sem_t s;
void *child(void *arg) {
printf("child\n");
sem_post(&s);
return NULL;
}
int main(int argc, char *argv[]) {
sem_init(&s, 0, X = 0);
printf("Parent begins\n");
pthread_t c;
pthread_create(&c, NULL, child, NULL);
sem_wait(&s); // wait for the child
printf("Parent ends");
return 0;
}NOTE: X should be 0, so the parent will go to sleep! There is NO share resource!
CASE: the parent is interrupted immediately after creating the child, then the order will also be correct
Setting the Value of a Semaphore
- 1 for lock, 0 for ordering.
The P/C (bounded) problem
Illustration


PROBLEM: race condition happens when MAX > 1 - Two or More threads try to edit the same thing.

NOTE: put the lock right just before and after the critical section only to avoid deadlock
PRACTICE: we allow many threads to read data at the same time, as long as they do not make any updates to data.
NOTE: for different operations, use different locks.
The dining philosophers
while (1) {
think();
get_forks(p);
eat();
put_forks(p);
}
int left(int p) { return p; }
int right(int p) { return (p + 1) % 5; }void get_forks(int p) {
sem_wait(&fork[left(p)]);
sem_wait(&fork[right(p)]);
}
void put_forks(int p) {
sem_post(&fork[left(p)]);
sem_post(&fork[right(p)]);
}
PROBLEM: deadlock again! when every one gets their left fork.
void get_forks(int p) {
if (p == 4) {
sem_wait(&forks[right(p)]);
sem_wait(&forks[left(p)]);
} else {
sem_wait(&forks[left(p)]);
sem_wait(&forks[right(p)]);
}
}
Thread throttling
- How to prevent too many threads from doing something at once and bogging the system down ⇒ define the threshold, then use the semaphore to limit the number of threads concurrently executing some code.
- Throttling, and consider it a form of admission control
- A simple semaphore can solve.
Illustration


Summary
- Semaphores are powerful and flexible primitive for writing concurrent programs
- Some programmers use them exclusively, shunning locks and condition variables, due to their simplicity and utility.
Week 11 - I/O Devices
System Architecture
Figures
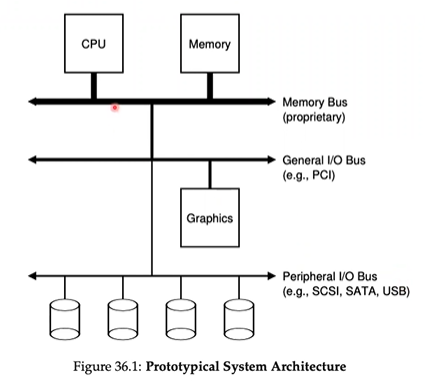
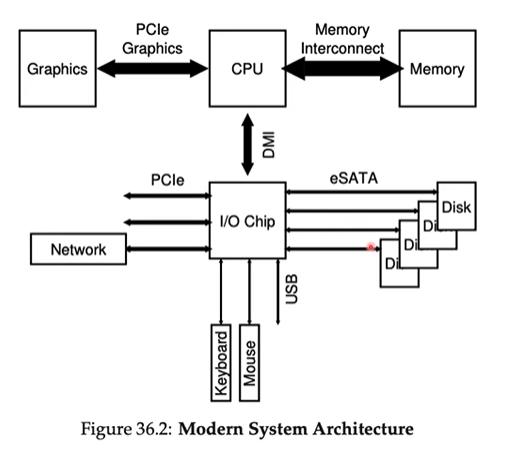
A canonical device
- All devices have some specified interface and protocol for typical interaction
- The internal structure is implementation-specific and is responsible for implementing the abstraction the device presents to the system.

- A status register can be read to see the current status of the device
- A command register is used to tell the device to perform a certain task
- A data register to pass data to the device or get data from the device
- By reading and writing these registers, the OS can control the device's behavior.

PROBLEM: wasting CPU time (polling)
Lowering CPU Overhead with Interrupts
SOLUTION: use a hardware interrupt
- If the system does something such as to get I/O, then the CPU goes to sleep, waits for being woken up.
Illustration
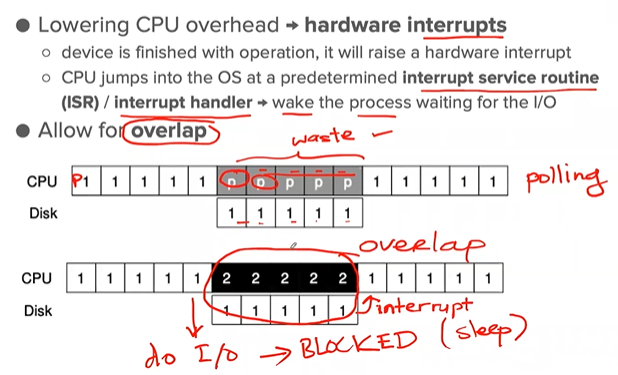
- If a device is fast → it may be best to poll; handling interruptions also causes overhead.
- If the speed of the device is not known, or sometimes fast and slow → using a hybrid that polls for a little while and then, if the device is not yet finished, uses interrupts
- Coalescing → an interrupt-based optimization, waits for a bit before delivering the interrupt to the CPU.
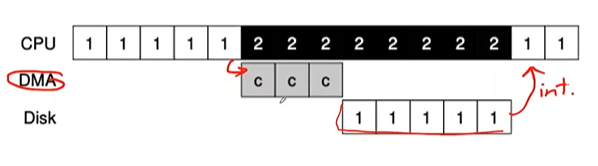
More efficient data movement with DMA
- When using programmed I/O (PIO) to transfer a large chunk of data to a device, the CPU is once again over-burdened with a rather trivial task, and thus wastes a lot of time and effort that could be spent running other processes.
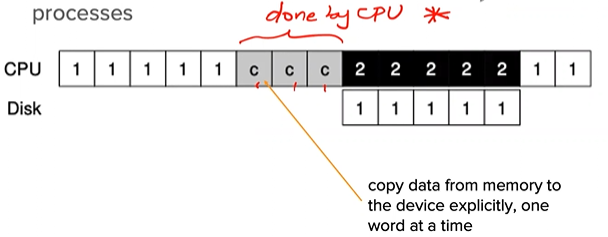
SOLUTION: Direct Memory Access (DMA)
- A DMA engine is essentially a very specific device within a system that can orchestrate transfers between devices and main memory without much CPU intervention
Methods of device interaction
- I/O instruction: privileged, OS controls devices
- Memory-mapped I/O: hardware makes device registers available as if they were memory locations
- OS must stay between the Process and Devices to control the behavior.
- To make sure the user doesn't abuse the devices.
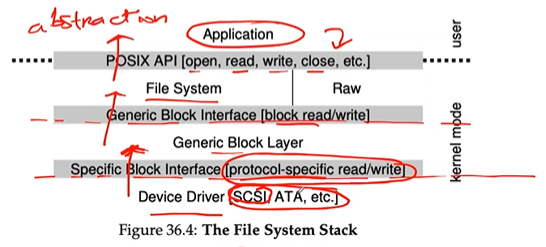
The device driver
- The problem is solved through the age-old technique of abstraction.
- At the lowest level, a piece of software in the OS must know in detail how a device works → device driver, and any specifics of device interaction are encapsulated within
Hard Disk Drives
Interface
- The drive consists of a large number of sectors (512-byte blocks), each of which can be read or written.
- The sectors are numbered from 0 → n - 1 on a disk with n sectors.
- Can view a disk as an array of sectors; 0 → n - 1 is thus the Address Space of the drive
- Multi-sector operations are possible; indeed, many file systems will read or write 4KB at a time or more
- When updating the disk, the only guarantee drive manufacturers make is that a single 512-byte write is atomic (complete, or not complete)
- if an untimely power loss occurs, only a portion of a larger write may complete (sometimes called a torn write)
Some assumptions
- Accessing two blocks near one another within the drive’s AP will be faster than 2 blocks that are far apart.
- Accessing blocks in a contiguous chunk (e.g: sequential read or write) is the fastest access mode, and usually much faster than any more random access pattern.
Basic geometry
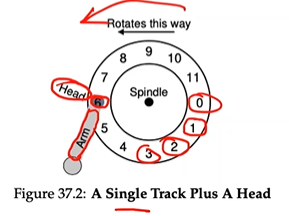
- Platter: a circular hard surface on which data is stored persistently by inducing magnetic changes to it.
- The platters are all bound together around the spindle, which is connected to a motor that spins the platters around (then the power is on) at a constant rate.
- Data is encoded on each surface in concentric circles of sectors; we call one such concentric circle a track. A single surface contains many Thousands and Thousands of tracks, tightly packed together, with Hundreds of tracks fitting into the width of a human hair.
- The process of reading and writing is accomplished by the disk head; there is one such head per surface of the drive.
- The disk head is attached to a single disk arm, which moves across the surface to position the dead over the desired track.
Simple disk drive
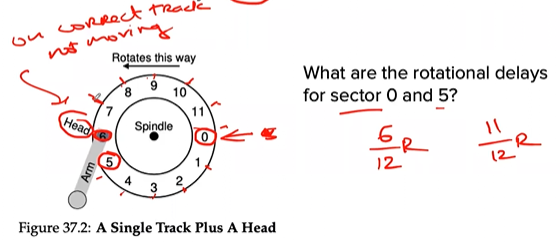
PROBLEM: single-track latency → rotational delay
- Time to wait for the desired sector to rotate under the disk head → rotational delay
- Full rotational delay is R
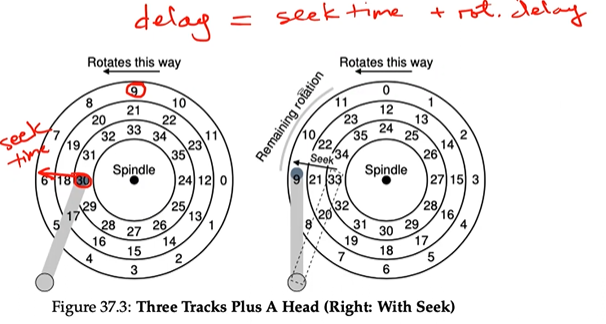
PROBLEM: in multiple tracks → seek time = disk head move to correct track
SOLUTION: Track skew
- Many drives employ some kind of track skew to make sure that sequential reads can be properly serviced even when crossing track boundaries.
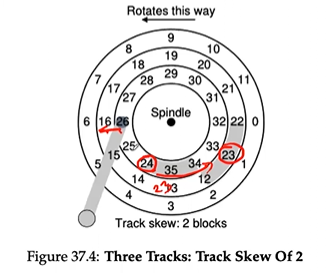
NOTE: other details
- Outer tracks tend to have more sectors than inner tracks → multi-zoned disk drives, each zone has the same number of sectors per track, and outer zones have more sectors than inner zones
- Cache (track buffer) → small memory (8 → 16MB) which the driver can use to hold data read from or written to the disk
- On writes, the drive has choices:
- Acknowledge the write has completed when it has put the data in its memory,
- After the write has actually been written to disk
- So-called write-back caching, immediate reporting, the latter write through
- Can lead to problems: the data in the cache memory can be swiped when power off.
I/O time
- transfer: time in which data is either read from or written to the surface
- Rate if I/O is often more easily used for comparison between drives (random workload vs sequential workload)
Illustration

Disk scheduling
- Given a set of I/O requests, the disk scheduler examines the requests and decides which one to schedule next.
- Disk scheduler will try to follow the principle of SJF
Shortest Seek Time First - SSTF
Pick the nearest track to complete first
PROBLEM:
- drive geometry is not available to the host OS → nearest-block-first - NBF
- starvation
Elevator - SCAN - C-SCAN
- SCAN → simply move back and forth across the disk servicing requests in order across the tracks
- single pass (outer-inner)
- F-SCAN → freezes the queue to be serviced when it is doing a sweep → to avoid starvation of far-away requests, by delaying the servicing of late-arriving (but nearer by) requests.
- Circular SCAN only sweeps from outer-to-inner → fair to inner and outer tracks, as pure back-and-forth SCAN favors the middle tracks.
- SCAN (or SSTF even) does not actually adhere as closely to the principle of SJF as they could, they ignore rotation.
Shortest Positioning Time First
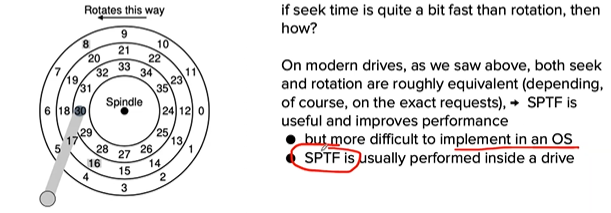
Other scheduling issues
- Where is disk scheduling performed on modern systems? Disk uses its internal knowledge of the head position (SPTF)
- I/O merging → important at the OS level to reduce the number of requests sent to disk → lower overheads
- How long should the system wait before issuing an I/O to disk?
- work-conserving immediately issue the request to the drive, as the disk will never be idle if there are requests to serve
- anticipatory disk scheduling has shown that sometimes it is better to wait for a bit → non-working-conserving approach.
Week 12 - Redundant Arrays of Inexpensive Disks (RAID)
Overview
- RAID is a technique to use multiple disks in concert to build a faster, bigger and more reliable disk system.
- Externally, a RAID looks like a disk: a group of blocks one can read or write.
- Internally, a RAID is a complex beast, consisting of multiple disks. memory and one or more processors to manage the system
- RAID is about a computer system specialized for the task of managing a group of disks.
Advantages of RAID:
- Performace
- Capacity
- Reliability
- Transparent
- Deployability
Interface and RAID internals
- To a file system (OS), a RAID looks like a big, hopefully fast, and hopefully reliable disk.
- When a file system issues a logical I/O request to the RAID, the RAID internally must calculate which disk or disks to access in order to complete the request, and then issue one or more physical I/Os to do so.
- Internally, however, RAIDs are fairly complex, consisting of
- a microcontroller that runs firmware to direct the operation of the RAID.
- volatile memory such as DRAM to buffer data blocks as they are read/written.
- non-volatile memory to buffer writes safety
- specialized logic to perform parity calculations
- At a high level, a RAID is very much a specialized computer system that runs specialized SW designed to operate the RAID.
Fault Model
Assumptions
- Using the fail-stop fault model: 2 states - working or failed
- Fault detection: when a disk has failed, we assume that this is easily detected.
How to evaluate a RAID
Three axes:
- Capacity: how much useful capacity is available to clients of the RAID
- N disks, B blocks, without redundancy → Capacity = N*B
- If a system keeps 2 copies (mirroring) → N*B/2
- Reliability: how many disk faults can the giving design tolerate?
- Performance: how fast
RAID 0: Striping
- No redundancy → is not reliable
- Serves as an excellent upper bound on performance and capacity.

- Spread the blocks of the arrays across the disks in a RR fashion
- Blocks in the same row a stripe
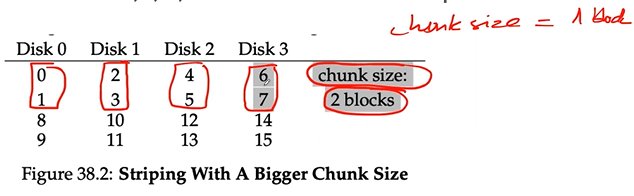
- Capacity: N*B
- Reliability: any disk failure will lead to data loss
- Performance is excellent → every disks are utilized to service user I/O requests (read/write in parallel)
Chunk size
- Mostly affects the performance of the array
- Small → files will get striped across many disks
- increasing the parallelism of reads/writes to a single file
- the position time to access blocks in disks is bigger
- Big
- reduce the intra-file parallelism → relies on multiple concurrent requests to achieve high throughput
- reduce positioning time → ex: a single file fits within a chunk and thus is placed on a single disk.
- Small → files will get striped across many disks
- Assume that the array uses a chunk size of a single block - 4KB for simplicity
Evaluating RAID Performance
- single-request latency: how much parallelism can exist during a single logical I/O operation
- steady-state throughput of the RAID. Ex: the total bandwidth of many concurrent requests.
- because RAIDs are often used in high-performance environments, so this is critical, and thus will be the main focus of analysis.
- Workloads
- sequential: a disk operates in its most efficient mode, spending little time seeking and waiting for rotation and most of its time transferring data.
- random → most time is spent seeking and waiting for rotation and relatively little time is spent transferring data.
- Assume a sequential transfer of size 10MB on average and a random transfer of 10KB on average. Also, assume the following characteristics:
- Avg seek time: 7ms
- Avg rotational time: 3ms
- Transfer rate of disk 50 MB/s
- Sequential workload
- Random workload
RAID 0: Striping (cont)
- Performance
- single-block request should be just about identical to that of a single disk.
- ready-state sequential throughput - full bandwidth of the system
- throughput = N * S = number of disks * sequential bandwidth of a disk
- For a large number of random I/Os → throughput = N * R (MB/s)
RAID 1: Mirroring
- Make more than one copy of each block in the system; each copy should be placed on a separated disk

- The arrangement above is a common one and is sometimes called RAID-10 (RAID 1+0, stripe of mirror)
- Another common arrangement is RAID-01 (RAID 0+1, mirror of stripes)
- Capacity: mirror level = 2, expensive, N * B / 2
- Reliability: can tolerate the failure of any 1 disk
- Performance:
- single-block request:
- a single read request is the same as the latency on a single disk
- a ‘write’ request → worst-case seek and rotational delay of the two requests of 2 mirrored disks, and thus on average will be slightly higher than a write to a single disk.
- steady-state throughput:
- sequential → maximum bandwidth = N/2*S
- random:
- random read, best case: N*R
- random write, N/2*R
- single-block request:
RAID 4: Saving space with parity
- Parity-based approaches attempt to use less capacity than mirrored systems at the cost of performance.
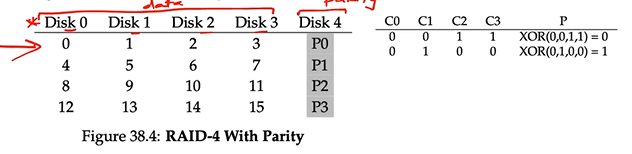
- Parity → the number of 1s in any row, including the parity bit, must be an even number
- XOR, if P = 0 ⇒ even 1s, if P = 1 ⇒ odd 1s
- Capacity: (N-1)*B
- Reliability: tolerate 1 disk failure and no more.
- Performance:
- stead-state throughput
- sequential:
- read delivers a peak effective bandwidth of (N-1)*S
- write: full stripe write
- random:
- read: (N-1)*R
- write: subtractive parity method
- bottleneck → small-write problem
- all writes will be serialized because only 1 parity disk
- parity disk has to perform 2 I/Os (read old value + calculate parity) → R/2
- sequential:
- stead-state throughput
RAID 5: Rotating Parity
- TO address the small-write problem → remove parity disk bottleneck

- Sequential read/write = RAID 4
- Random read is better, N disks
- Random write performance improves noticeably over RAID 4
- Total bandwidth for small write = N/4*R
- RAID 5 is almost identical to RAID 4 → almost complete replaced RAID 4 in the marketplace
RAID Comparison

Files and Directories
- Each file has some kind of low-level name, usually a number of some kind often referred to as its inode number
- Directory Tree
- Root directory /
- Absolute pathname
- Type (.docx...)
Creating files
Illustrations
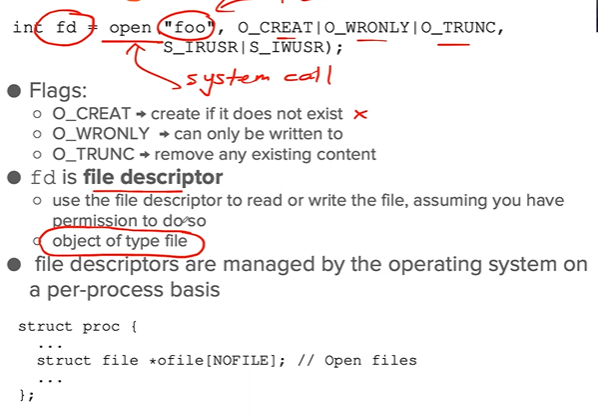

fd
- 0 → stdin
- 1 → stdout
- 2 → stderr
Read/write but not sequentially
Shared file table entries
Writing immediately with fsync()
Remaining files (move)
Getting information about files
Removing files
Making directories
Making directories
Removing directories
Hard links
Symbolic links - soft links
Permission bits and access control lists
Making and mounting a file syste
Week 13 - File System Implementation
- data structures of the file system → on-disk structured used to organize data and metadata.
- access methods → how to map the calls, such as open(), read(), write() made by a process onto its structures.
Overall Organization
- Divide disk → blocks - 4KB
- Disk partition → a series of N 4KB-blocks
- Blocks are addressed from 0 to N - 1 (disk address)
- Assume we have a really small disk with just 64 blocks
- Sector ~ 512B
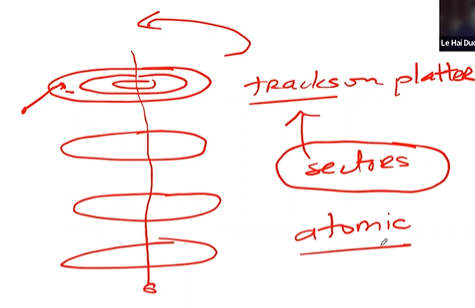
- data region → region of the disk used for user data

- metadata → track information about each file (size, owner, access rights, access and modify times...)
- stored in a structure called an inode ⇒ reserve disk for them called inode table (array of on-disk inodes)
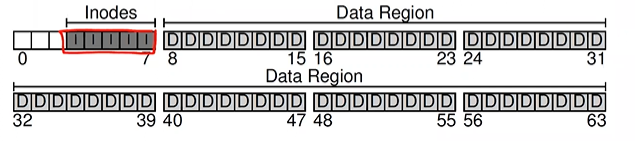
- to track whether inodes or data blocks are free or allocated ⇒ allocation structures
- free list → point to the first free block, which then points to the next free block, and so forth
- bitmap → one for the data region (data bitmap) and one for inode table (inode bitmap)
- each bit indicates the object/block is free (0) or in-use (1)
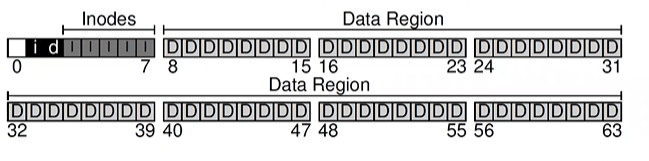
- superblock → contains information about this particular file system
- how many inodes and data blocks are in the file system (80 and 56)
- magic number → identifies the file system type
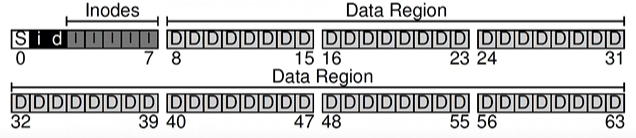
- when mounting a file system, OS reads superblock first to initialize various parameters, then attach the volume (disk partition) to the file-system tree
File organization: The inode
- all file systems have a structure similar to inode (index node)
- each inode is implicitly referred to by a number called i-number = the low-level name of the file
Example - Inode
- inode contains information - metadata about: type, size, number of blocks allocated to it, protection information, time, where its data blocks reside on disk
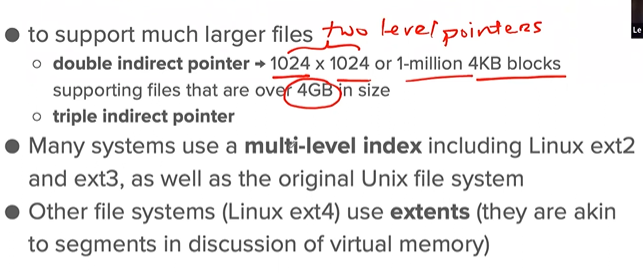
- How to refer to where data blocks are?
- direct pointers - disk addresses, in inode
- limited: file that is bigger than the block size multiplied by the number of direct pointers in the inode.
- indirect pointer - multilevel index, points to a block that contains more pointers, each of which points to user data
- direct pointers - disk addresses, in inode
EXAMPLE

SUMMARY

Directory organization
- A directory contains a list of pairs (entry name, inode number)
- Each file, directory in a given directory contains a string and a number in the data blocks of the directory
- Each string can contain a length (assuming variable-sized names)

- Deleting a file (calling unlink()) can leave an empty space in the middle of the dir, and hence there should be some way to mark that as well (with a reserved inode number such as Zero)
- File systems treat dirs as a special type of file. Thus, a dir has an inode, somewhere in the inode table (type: “directory” instead of “regular file”)
Free space management
- in vsfs, use 2 simple bitmaps for tracking which inodes and data blocks are free.
- some Linux file systems will look for a sequence of blocks that are free when a new file is created and needs data blocks → improve performance (pre-allocation policy)
Access paths: reading and writing
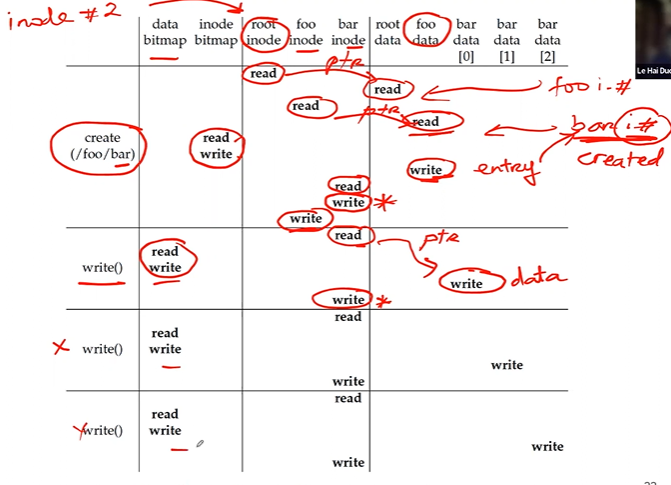
Reading a file from disk
- the file system must traverse the pathname starting from root dir and thus locate the desired inode.
Illustration - READ bar/foo

Illustration - WRITE bar/foo
Caching and buffering
- reading and writing files can be expensive, incurring many I/Os to the slow disk.
- most file systems aggressively use system memory DRAM to cache important blocks
- early file system → fixed-sized cache
- static partitioning → allocating fixed-size cache at boot time to be roughly 10% of total memory → could be wasteful
- dynamic partitioning → integrates virtual memory pages and file system pages into a unified page cache.
- early file system → fixed-sized cache
- write buffering ⇒ batch some updates into a small set of I/O
- the system can then schedule the subsequent I/Os and thus increase performance
- some writes are avoided altogether by delaying them.
Fast file system
Solution 1: small block size
- Minimize internal fragmentation - reduce waste inside block
- but, bad for transfer → positioning overhead


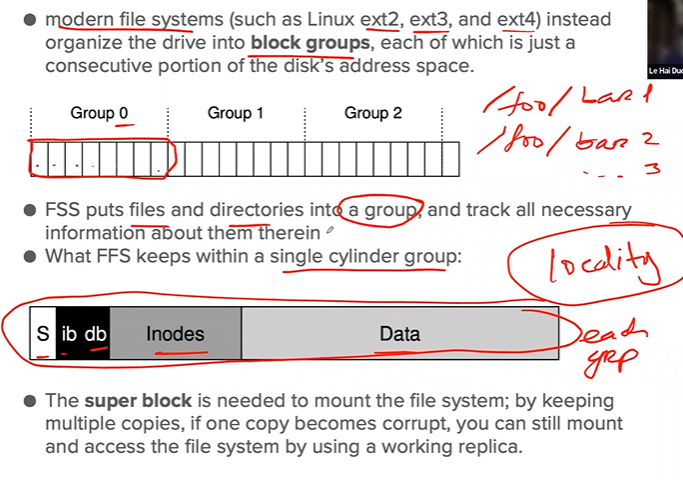
Policies: how to allocate files and directories
Large-file exception
Week 14 - Crash Consistency: FSCK and Journaling
Challenge faced by a file system is how to update persistent data structures despite the presence of a power loss or system crash
→ crash-consistency problem
Methods:
- fsck (file system checker)
- journaling (write-ahead logging)
A detailed example


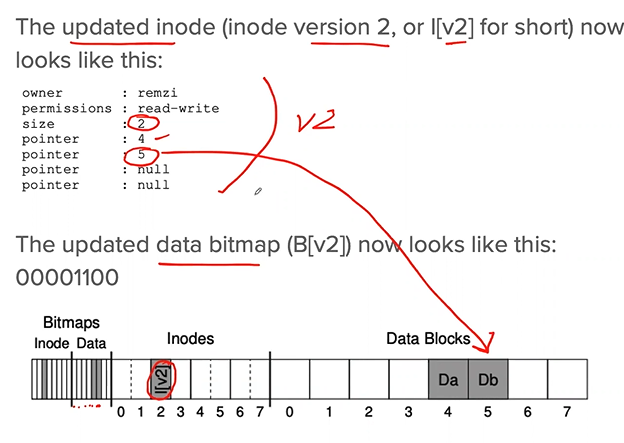
PROBLEM: 3 separately write()s to the disk, then
- page cache, buffer cache cause the change does not happen immediately (5 - 30 s)
- then if there is a crash, it interferes with these updates, so not all the writes will complete, so it leads to a funny state - inconsistency.
Crash scenarios
- Just the Data Block is written to disk: file is not updated despite the data block being changed ⇒ Still OK
- Just the inode is written to disk: pointer to data block is updated, but there is no data at all! then the reads will get garbage ⇒ Inconsistency!
- Just the bitmap is written to disk: the data block is marked as used, but there is no data, and no one can use it ⇒ Space leak.
- The inode and the bitmap are written: consistency metadata but there is garbage
- The inode and the data block are written: can read the right data, but, inconsistency, 2 files can point to the same block.
- The bitmap and data block are written: the block is marked as used, the data block is used, but no one can use it. Inconsistency.
Solution 1: fsck
- is a UNIX tool for finding such inconsistencies and repairing them
- it is run before the file system is mounted and made available
- it does the basics such as:
- superblock: checks if the superblocks look reasonable, make sure the FS size is greater than the number of blocks that have been allocated
- free block: scans the inodes, indirect blocks, double indirect blocks ... to build an understanding of which blocks are currently allocated within the FS.
- it uses this knowledge to produce a correct version of the allocation bitmaps → to resolve any inconsistency between bitmaps and inodes.
- the same type of check is performed for all the nodes, making sure that all inodes that look like they are marked as such in the inode bitmaps
- inodes state: check for corruption or other problems...
- inodes links: verifies the link count of each allocated inode
- scans entire dir, and then builds its own link counts for every file and dir.
- if there is a mismatch, corrective action must be taken: fixing the count within the inode, if the allocated inode is discovered but there is no dir refers to, then it is moved to lost and found dir.
- duplicates: checks for duplicate pointers (ex: 2 inodes refer to the same block)
- if one is bad, then clear it.
- or can copy the pointers for each inode
- bad blocks: check bad blocks pointers → if any, then remove them
- directory checks: check the integrity, maker sure “..” or “.” are the first entries, make sure no dir is linked more than once, or circle hierarchy
PROBLEMS of fsck:
- require intricate knowledge of the file system
- they are too slow to scene the whole FS
Solution 2: Journaling - write-ahead logging
- Idea from the world of database management systems - write-ahead logging
- Many modern FS use this idea: Linux, IBM, Windows NTFS
- The basic idea:
- When updating the disk, before overwriting the structure in place, first write down a little note (in somewhere else on the disk, in a well-known location) describing what you are about to do.
- Writing this note is the write-ahead part, and we write it to a structure that we organize as a log → write-ahead logging
- Know exactly what to fix and how to fix it after a crash, instead of having to scan the entire disk
Data journaling
- Assuming to write inode, bitmap, and data block to the disk.
- Before writing, we first write them to the log (journal).

- TxB includes info about the spending update to the FS and some kind of transaction-id
- Once TID is safely put on disk → ready → overwrite the old structure in the FS - checkpointing
- What will happen...
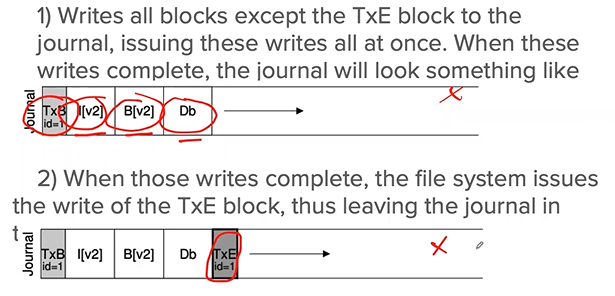
- Journal write: write the contents of the transaction (TxB, metadata, data) to the log, wait for these writers to complete
- Journal commit: write the transection commit block (containing TxE) to the log, wait for the write to complete, the transaction is said to be committed.
- Checkpoint: write the contents of the update (metadata and data) to their final on-disk locations.
Recovery
- if a crash happens, the transaction is committed to the log, but the checkpoint is incomplete, the FS can recover as follow:
- when the system boots, the FS process will scan the log and look for transactions that have committed to the disk; these transactions are thus replayed in order, with the FS again attempting to write out the blocks in the transaction to their final on-disk locations. This form of logging is one of the simplest forms there is and is called redo logging.
- It is fine for a crash to happen at any point during checkpointing, even after some of the updates have been made.
- There can be a few redundancies, but it’s fine!
Batch log updates
Buffer all updates into a global transaction → file system can avoid excessive write traffic to this in many cases.
Make the log finite
- Cause the log is of a finite log, so it will soon fill,
- Journaling then can treat the log as a circular data structure, re-using it over and over again
Add other steps to the basic
- Free: sometime later, mark the transaction free in the journal by updating the journal superblock
PROBLEM: data block is written TWICE, so it is expensive
Solution: Metadata Journaling (Ordered Journaling)

Blocked reuse
Timeline of the two kinds of journaling